8月9日消息,阿里通义团队开源新一代数学模型qwen2-math,包含1.5b、7b、72b三个参数的基础模型和指令微调模型。qwen2-math基于通义千问开源大语言模型qwen2研发,旗舰模型 qwen2-math-72b-instruct在权威测评集math上的得分超越gpt-4o、claude-3.5-sonnet、gemini-1.5-pro、llama-3.1-405b等,以84%的准确率处理了代数、几何、计数与概率、数论等多种数学问题,成为最先进的数学专项模型。
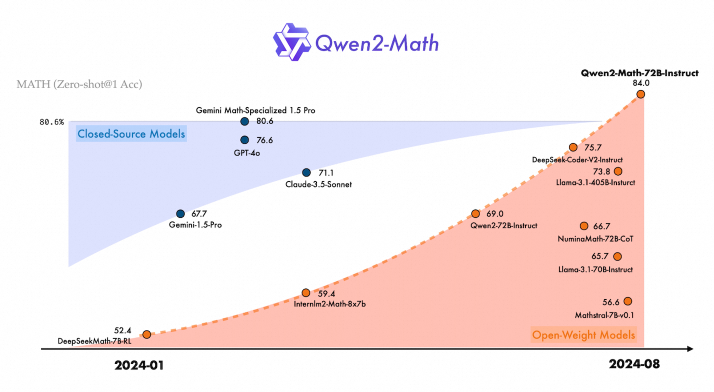
注:在math基准测评中,通义千问数学模型的旗舰款qwen2-math-72b-instruct取得了84%的准确率,超过gpt-4o、claude-3.5-sonnet、gemini-1.5-pro 和 llama-3.1-405b等开闭源模型。
qwen2-math 基础模型使用 qwen2大语言模型进行初始化,并在精心设计的数学专用语料库上进行预训练,训练数据包含大规模高质量的数学网络文本、书籍、代码、考试题目,以及由 qwen2 模型合成的数学预训练数据。所有预训练和微调数据集都进行了去污染处理。
随后,研发团队训练了指令微调版本模型:基于qwen2-math-72b 训练一个数学专用的奖励模型;接着,将密集的奖励信号与指示模型是否正确回答问题的二元信号结合,用作学习标签,再通过拒绝采样构建监督微调(sft)数据;最后在sft模型基础上使用 grpo 方法优化模型。
据悉,qwen2-math系列模型目前主要支持英文,通义团队很快就将推出中英双语版本,多语言版本也在开发中。
通义团队在多个中英文数学基准测评集对指令微调模型作了性能评估,除了 gsm8k 和 math等常见的测评基准 ,还引入了更具挑战性的考试竞赛类测试,如奥林匹克级别的基准测评olympiadbench、大学数学级别的基准测评collegemath、高考(gaokao)、美国数学邀请赛(aime)2024 赛题、美国数学竞赛( amc)2023赛题,中文测评则有cmath测评集、2024年中国高考和中考数学题。最终,qwen2-math-72b-instruct表现优异,在十大测评中都获得了远超其他开源数学模型的成绩。
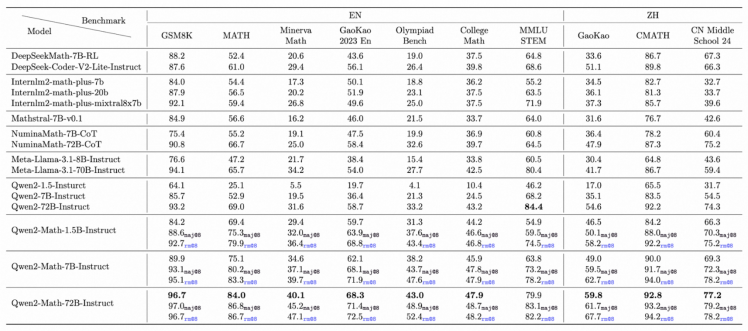
注:研发团队在greedy和rm@8 的条件下对模型作了测评,表中为每款qwen2-math-72b-instruct模型列出了三个得分结果,分别是第1次回答得分(无下标数字)、8次回答中出现最多次数的答案的得分,8次回答中reward model所选答案的得分。
“大模型能不能做数学题”,不仅是社交平台的热门话题,也是业界非常关注的研究课题。处理高级数学问题,需要模型具备复杂多步逻辑推理能力。通义团队在技术博客中表示,希望通过开源“为科学界解决高级数学问题做出贡献”,未来将持续增强模型数学能力。
附:qwen2-math解题示例